

 Sortie de CUDA 10, l'API de calcul sur processeur graphique de NVIDIA,
Sortie de CUDA 10, l'API de calcul sur processeur graphique de NVIDIA,avec la possibilité de définir ses calculs comme un graphe de dépendances
]Dans le mois de lannonce de CUDA 10, NVIDIA lance effectivement la nouvelle version de son API de calcul sur processeur graphique. Outre la gestion de la nouvelle architecture Turing, cette version 10 apporte bon nombre de nouveautés, partiellement déjà annoncées.
Une grande nouveauté de CUDA 10 facilitera lexpression de programmes de calcul compliqués, où certaines opérations ne peuvent être lancées que quand dautres sont terminées : par exemple, on ne peut copier les résultats dun calcul sur le processeur central que quand il a fini de sexécuter sur la carte graphique. CUDA disposait déjà de la notion de flux, mais elle nautorisait pas une grande flexibilité : le processeur central doit toujours gérer lordonnancement des tâches, par exemple. Lancer un noyau de calcul prend toujours un certain temps, non négligeable quand le noyau est assez petit.
Lidée des graphes de calcul est donc dindiquer à CUDA les tâches à exécuter et leurs dépendances, de telle sorte que la carte graphique ou le pilote puisse décider, sans attendre lapplication, des tâches à exécuter par la suite. Dans le cas de noyaux très rapides à lexécution dans un processus plus long, les coûts de lancement sont en grande partie éliminés. Également, CUDA peut réordonner les tâches afin daméliorer les temps dexécution, notamment en réduisant les mouvements de données : la carte graphique sait quand des données seront réutilisées, par exemple.
| Code : | Sélectionner tout |
1 2 3 4 5 6 7 8 9 10 | cudaGraphCreate(&graph);
cudaGraphAddNode(graph, kernel_a, {}, ...);
cudaGraphAddNode(graph, kernel_b, { kernel_a }, ...);
cudaGraphAddNode(graph, kernel_c, { kernel_a }, ...);
cudaGraphAddNode(graph, kernel_d, { kernel_b, kernel_c }, ...);
cudaGraphInstantiate(&instance, graph);
for(int i = 0; i < 100; i++)
cudaGraphLaunch(instance, stream); |
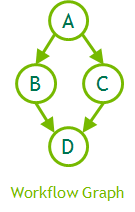
Source : CUDA 10 Features Revealed: Turing, CUDA Graphs and More.
Et vous ?
 Qu'en pensez-vous ?
Qu'en pensez-vous ?
Vous avez lu gratuitement 4 666 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

