

 Lapprentissage profond (appellation souvent remplacée par intelligence artificielle, à la demande du marketing) est de plus en plus présent dans la vie de tous les jours. Notamment, cette technique dapprentissage automatique a permis de grands progrès dans la reconnaissance vocale, à lorigine de produits comme Amazon Alexa. Avec les assistants vocaux sur téléphone, il devient important darriver à exécuter de grands réseaux neuronaux au niveau dun téléphone mobile, cest-à-dire sans grande consommation énergétique. Cest pourquoi ARM sest lancé dans la conception de processeurs spécifiquement prévus pour ces tâches.
Lapprentissage profond (appellation souvent remplacée par intelligence artificielle, à la demande du marketing) est de plus en plus présent dans la vie de tous les jours. Notamment, cette technique dapprentissage automatique a permis de grands progrès dans la reconnaissance vocale, à lorigine de produits comme Amazon Alexa. Avec les assistants vocaux sur téléphone, il devient important darriver à exécuter de grands réseaux neuronaux au niveau dun téléphone mobile, cest-à-dire sans grande consommation énergétique. Cest pourquoi ARM sest lancé dans la conception de processeurs spécifiquement prévus pour ces tâches.
ARM a regroupé plus de cent cinquante personnes pour travailler sur ce processeur, avec des expériences variées : processeurs principaux (CPU), processeurs graphiques (GPU), processeurs de traitement du signal (DSP). Larchitecture est prévue pour fonctionner à diverses échelles, depuis des applications embarquées ou de lInternet des objets jusquà des serveurs haut de gamme ou des voitures. La première génération se focalise sur les téléphones mobiles, mais avec des dérivés pour dautres segments. Ils devraient être disponibles cette année, au moins en licence.
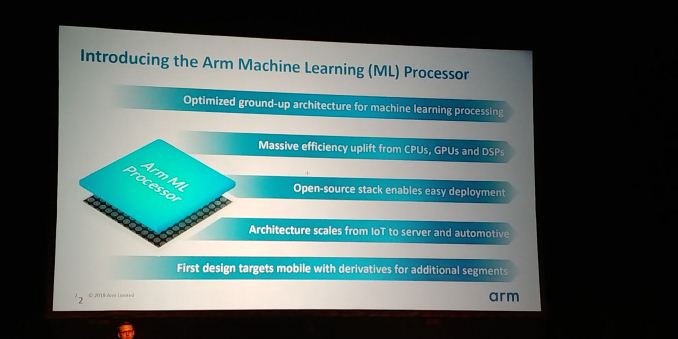
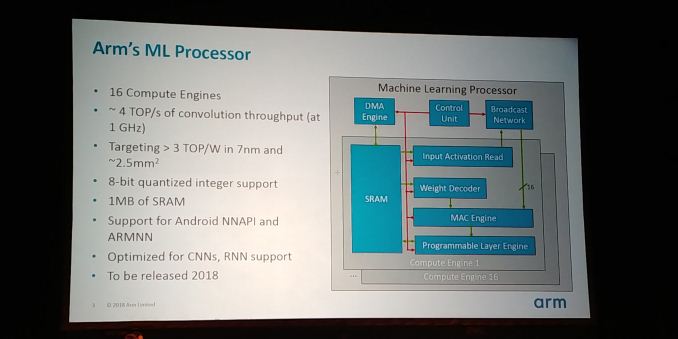
Larchitecture de ces processeurs est conçue dès le départ pour être efficace pour des réseaux neuronaux de grande taille, particulièrement convolutionnels ou récurrents. Un processeur ML est constitué de seize moteurs de calcul, mais surtout dune grande mémoire statique, un mégaoctet de cache. Lobjectif est datteindre trois téraopérations par watt en utilisant une surface de deux millimètres carrés et demi, avec un processus de fabrication en sept nanomètres. En pratique, la convolution peut être effectuée à raison de quatre téraopérations par seconde à la fréquence dun gigahertz. Ces processeurs sont prévus pour implémenter lAPI NNAPI dAndroid. En pratique, ces processeurs orientés apprentissage profond ont été conçus à partir des ARM Cortex-M, des puces à très basse consommation auxquelles les développeurs ont ajouté des instructions spécifiques pour les réseaux neuronaux (un cur Cortex-M par moteur de calcul).
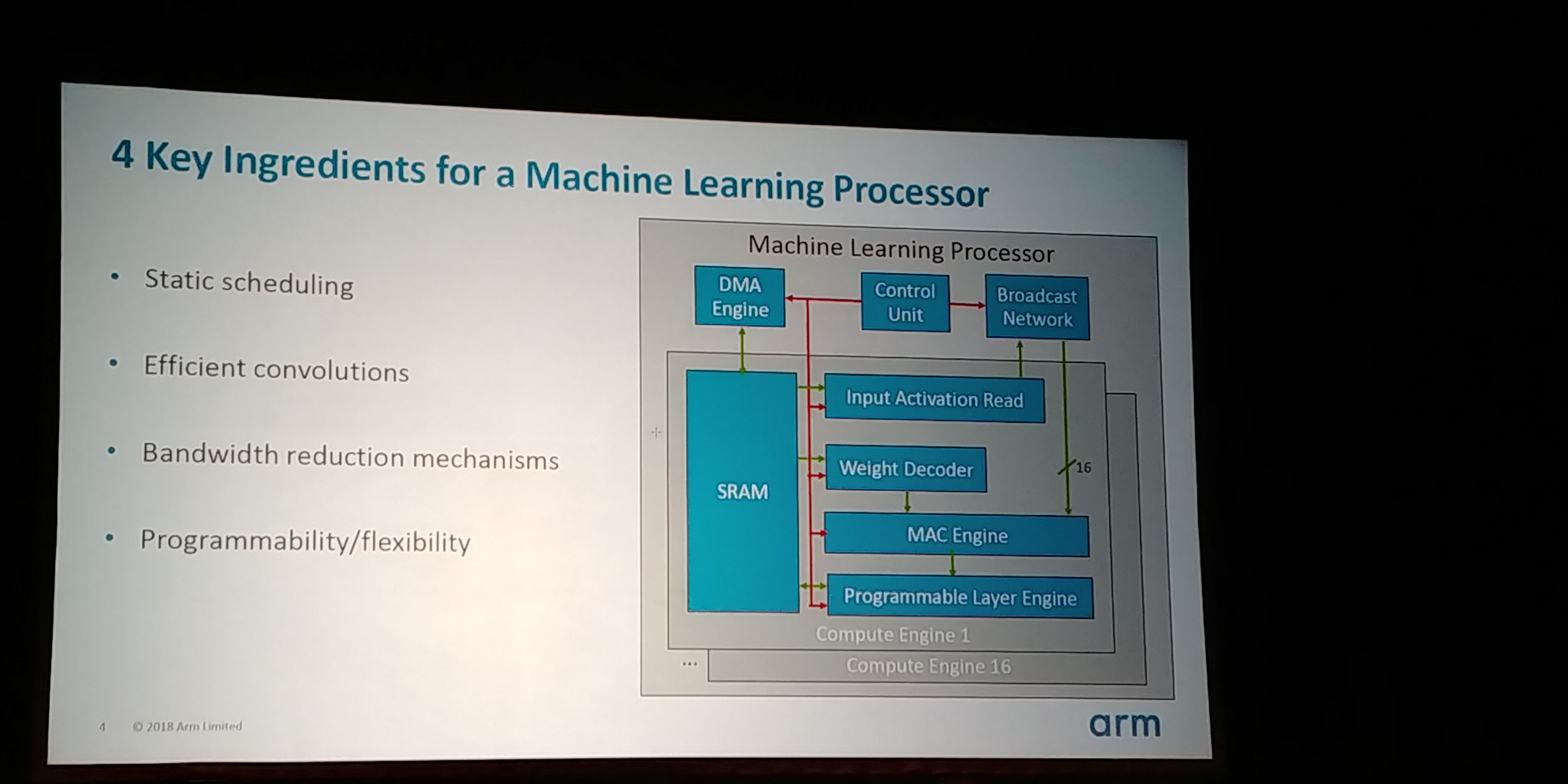
Pour un tel processeur, il faut faire attention à quatre points particuliers. Tout dabord, un ordonnancement statique des instructions, puisque les opérations à exécuter sont relativement peu variées. Ensuite, une implémentation efficace des convolutions, ce qui est facilité par leur côté très statique : on peut prévoir à lavance, en mémoire, toutes les données nécessaires pour effectuer une convolution aussi rapidement que possible (mélanger intelligemment les poids de la convolution avec les données pour exploiter au mieux les caches). Le compilateur, connaissant la taille de la mémoire statique disponible, peut effectuer ce genre doptimisations.
Troisièmement, la réduction de la bande passante utilisée en mémoire. En effet, la mémoire dynamique (externe au processeur) peut consommer autant que le processeur : moins il y a de communications, plus la consommation dénergie est limitée. Pour y arriver, ARM a développé de nouvelles techniques de compression des réseaux neuronaux, qui sexécutent entièrement au niveau du processeur (non de la compilation). Ces techniques se basent surtout sur le fait que, après lapprentissage, de très nombreux poids sont proches de zéro : les mettre à zéro change peu la précision du réseau, mais permet déconomiser beaucoup dénergie.
Le quatrième élément est une grande programmabilité, ici atteinte avec un moteur programmable pour chacune des couches du réseau, de telle sorte que de futures architectures puissent fonctionner sur ces processeurs.
Source : Hot Chips 2018: Arms Machine Learning Core Live Blog.
Vous avez lu gratuitement 121 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.