

 Cela fait déjà quelque temps que Fujitsu a annoncé que le prochain supercalculateur japonais, dénommé Post-K, utiliserait l’architecture ARM (au lieu de SPARC, pour K), afin d’atteindre une puissance d’un exaflops (un milliard de milliards d’opérations par seconde). À l’occasion de la conférence IEEE Hot Chips, Fujitsu détaille un peu plus son processeur, nommé A64FX.
Cela fait déjà quelque temps que Fujitsu a annoncé que le prochain supercalculateur japonais, dénommé Post-K, utiliserait l’architecture ARM (au lieu de SPARC, pour K), afin d’atteindre une puissance d’un exaflops (un milliard de milliards d’opérations par seconde). À l’occasion de la conférence IEEE Hot Chips, Fujitsu détaille un peu plus son processeur, nommé A64FX.
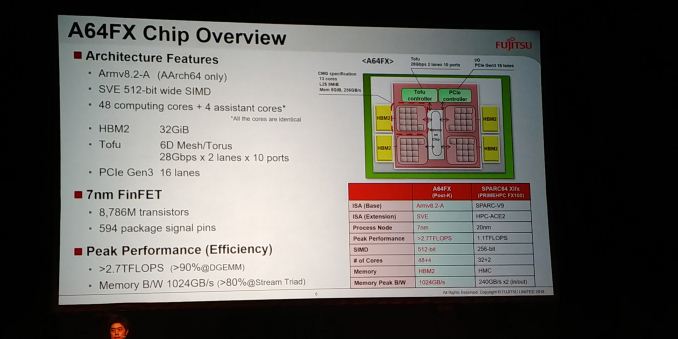
Quelques chiffres sur l’A64FX. Il sera constitué de 7,86 millions de transistors, connecté à la carte mère par cinq cent nonante-quatre broches, fabriqué avec un processus à 7 nm (FinFET). Il n’implémentera l’architecture qu’en 64 bits (AArch64), sans compatibilité 32 bits. L’extension SVE (scalable vector extension) sera de la partie (l’A64FX devrait être le premier processeur à l’implémenter), avec une largeur de cinq cent douze bits. Chaque processeur sera constitué de quarante-huit cœurs, plus quatre cœurs qui les assisteront dans des tâches comme les entrées-sorties (de manière générale, le système d’exploitation devrait s’exécuter sur ces cœurs).

Fujitsu a maintenant annoncé quelques chiffres sur la performance de ces processeurs : pour des opérations à virgule flottante à double précision (FP64), une puce pourrait monter à 2,7 Tflops (mille milliards d’opérations par seconde) ; en simple précision (FP32), le processeur irait deux fois plus vite (5,4 Tflops), même chose en demi-précision (10,8 Tflops en FP16). Côté nombres entiers, il pourrait aller aussi vite pour le même nombre de bits par nombre : 10,8 Tflops pour des entiers sur seize bits (INT16), 21,6 Tflops pour huit bits (INT8).

Ces nombres sont déjà étonnants par le fait que la performance pour des entiers n’est pas supérieure à celle pour les nombres à virgule flottante, car les opérations sont plus simples. Aussi, ces chiffres sont très proches des processeurs Intel : trente-cinq pour cent supérieurs aux processeurs généraux Xeon de génération Skylake, vingt pour cent inférieurs aux processeurs spécifiques au calcul parallèle Xeon Phi. Intel prépare certainement des processeurs plus rapides pour 2021, quand l’A64FX devrait arriver sur le marché — et probablement avec une efficacité énergétique améliorée. Ces nombres indiquent qu’il faudrait approximativement au moins trois cent septante mille processeurs pour atteindre l’exaflops théorique (et plus pour des tests de performance réels, comme Linpack, puisque doubler le nombre de processeurs ne double pas directement la performance à cause des communications qui doivent s’établir). Bien entendu, ceci s’entend sans amélioration de la part de Fujitsu d’ici à la construction de la machine, ce qui semblerait étonnant.
Au niveau architectural, le réseau du superordinateur Post-K (nommé Tofu) sera organisé comme un tore à six dimensions, de telle sorte que chaque processeur aura dix ports à vingt-huit gigabits par seconde, dans chaque sens (pour un total de cinq cent soixante gigabits par seconde par processeur). Le contrôleur réseau est directement inclus dans les processeurs A64FX.
Les cinquante-deux cœurs du processeur sont divisés en quatre groupes : douze cœurs de calcul, un cœur assistant, une pile de mémoire HBM2 (huit gigaoctets par groupe, c’est-à-dire trente-deux gigaoctets par processeur) à un téraoctet par seconde. Ces groupes sont nommés CMG (core memory group). Chaque cœur dispose de soixante-quatre kilooctets de cache de premier niveau, avec un débit maximum de onze térabits par seconde. Les huit mégaoctets de cache de deuxième niveau (3,6 To/s) sont partagés par tous les cœurs d’un groupe et sont connectés au réseau intérieur du processeur (qui donne accès aux autres groupes et aux contrôleurs réseau et PCIe).

Les cœurs disposent de fonctionnalités d’exécution en désordre, de prédiction de branchement, d’exécution superscalaire. Par exemple, les instructions FMA (fused multiply-and-add), extrêmement utiles pour le calcul scientifique (elles permettent d’implémenter très efficacement les produits matriciels : a <- b + c * d), pourront disposer de quatre opérandes distincts, de telle sorte que la sortie de l’opération n’écrase pas un opérande — les instructions de l’extension SVE d’ARM sont limitées à trois opérandes. L’architecture ARM prévoit que cette opération s’effectue avec deux instructions distinctes (MOVPRFX pour spécifier le registre de sortie, FMA3 pour le calcul proprement dit, effectué de manière destructive), mais l’A64FX fusionnerait ces deux instructions en une seule au niveau de l’exécution. Ce genre d’optimisation permet de monter très haut en efficacité.

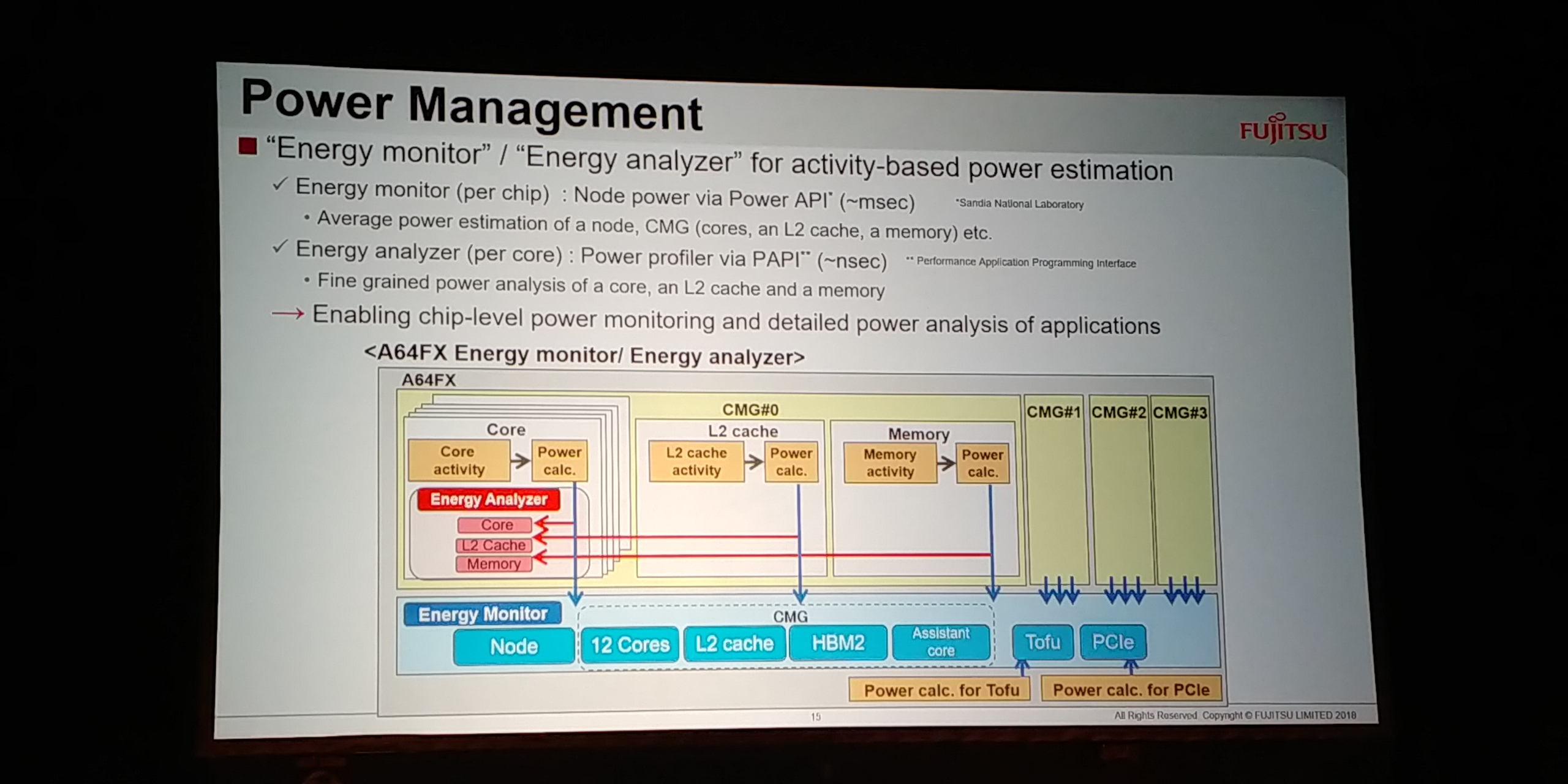
Bien évidemment, pour un superordinateur de la taille du Post-K, l’énergie est un facteur très important (c’est à cause de la consommation énergétique que l’on ne peut pas construire de superordinateur de cette échelle avec le matériel actuel). Ainsi, chaque puce surveillera sa consommation d’énergie avec une résolution d’une milliseconde, chaque cœur à la nanoseconde près.
Au niveau logiciel, Fujitsu travaille avec le centre de recherche RIKEN, qui recevra le Post-K. Notamment, Fujitsu prépare un compilateur spécifiquement optimisé pour la microarchitecture de l’A64FX. Les développements sont réalisés avec des partenaires comme Linaro et bénéficieront à la communauté ARM en général.

Sources et images : Fujitsu Reveals Details of Processor That Will Power Post-K Supercomputer, Hot Chips 2018: Fujitsu’s A64FX Arm Core Live Blog.
Vous avez lu gratuitement 47 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

