

 NVIDIA annonce la nouvelle version de CUDA
NVIDIA annonce la nouvelle version de CUDAL'API de calcul sur processeur graphique s'enrichit d'une bibliothèque de décodage d'images JPEG
En même temps que la sortie de sa nouvelle génération de cartes graphiques (Turing), NVIDIA annonce la prochaine version de sa suite logicielle pour lexécution de codes de calcul sur ses processeurs graphiques : CUDA 10. Cette API est loin dêtre remplacée par OpenCL et NVIDIA sefforce de garder une certaine avance par rapport à lAPI concurrente (mais librement implémentable). CUDA 10 nest pas encore disponible au téléchargement, mais sa version finale sortira en 2018.
La version 10, outre la gestion des cartes Turing, apporte des améliorations habituelles de performance dans ses bibliothèques de calcul : la transformée de Fourier rapide (FFT) sexécute plus vite sur plusieurs GPU (NVIDIA parle même de mise à léchelle forte sur seize cartes), les routines dalgèbre linéaire dense (factorisation de Cholesky et valeurs propres) sont plus rapides, certains noyaux ont été optimisés pour les spécificités de gestion des précisions multiples de Turing.
Une nouvelle bibliothèque fait son apparition : nvJPEG, pour le décodage dimages au format JPEG (une par une ou bien en lot) et la conversion despaces colorimétriques. Le décodeur peut fonctionner tant uniquement sur la carte graphique quen mode hybride, en exploitant aussi le CPU. Les avantages sont un meilleur débit et une latence diminuée : nvJPEG peut décoder plus dimages par seconde quun CPU, mais prend aussi moins de temps par image. Ses applications prévues sont la vision par ordinateur, notamment par apprentissage profond : la plupart des images utilisées sont au format JPEG, qui prend relativement peu de place sur le disque. En sus, nvJPEG peut effectuer certaines opérations directement au même moment que le chargement, comme des translations, une mise à léchelle, etc. Une préversion est déjà disponible.
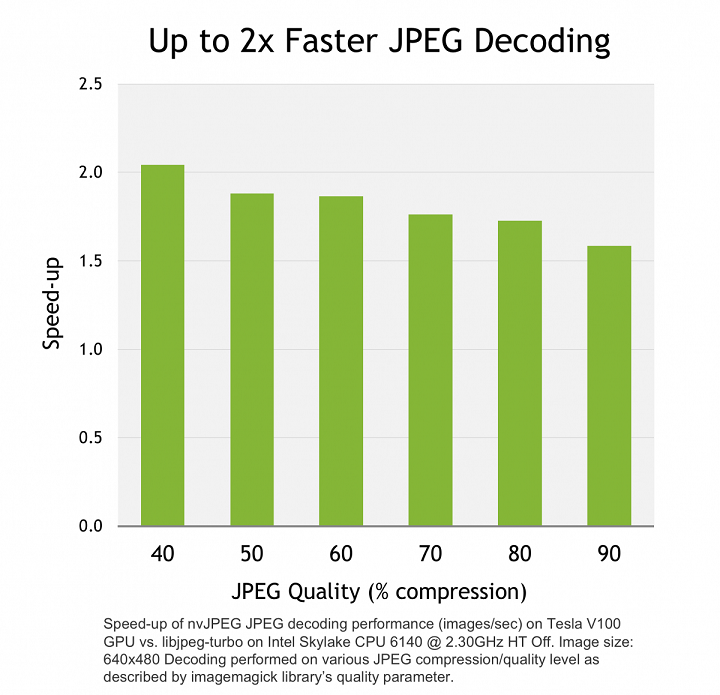
Dans les nouvelles fonctionnalités, on compte aussi un nouveau mécanisme dinteropérabilité avec les API de rendu comme DirectX 12 et Vulkan, à destination principalement des applications en temps réel comme les jeux. La famille doutils de développement Nsight senrichit de Systems (pour lanalyse de performance à léchelle dun système complet) et de Compute (plus spécifiquement pour les noyaux de calcul, avec une collection de données rapide et une interface entièrement programmable).
La microarchitecture de Turing promet également des modifications au niveau des capacités de calcul (Compute Capability). Par exemple, les curs tensoriels peuvent fonctionner avec dautres précisions : jusquà présent, ils étaient limités à des nombres à virgule flottante sur demi-précision (seize bits) ; avec Turing, ils pourront descendre jusque des entiers sur huit et même quatre bits (avec des calculs respectivement deux et quatre fois plus rapides). Sur certaines applications, ces quelques modifications seront probablement très utiles à NVIDIA pour garantir une performance excellente mais seulement sur quelques niches : avec quatre bits, on ne peut représenter que seize valeurs différentes

Les multiprocesseurs de flux (SM) évoluent également, dans les curs de calcul (CUDA). Notamment, Volta avait séparé les parties effectuant des calculs sur des entiers, de telle sorte quil devient possible de travailler, exactement en même temps, sur des entiers et des nombres à virgule flottante. Ceci permet daccélérer grandement des opérations de génération dadresse, notamment.
Les unités arithmétiques et logiques de ces multiprocesseurs voient aussi la gestion des précisions inférieures de manière plus générale : toutes les opérations autrefois exclusivement FP32 peuvent être effectuées avec une précision moindre (FP16), à une vitesse double. Ceci était utile pour les réseaux neuronaux, mais lest tout autant pour certains jeux.

Sources : Announcing CUDA Toolkit 10, NVIDIA Reveals Next-Gen Turing GPU Architecture: NVIDIA Doubles-Down on Ray Tracing, GDDR6, & More.
Vous avez lu gratuitement 6 760 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

